akka Performance
akka performance.
- 성능에 관한 일반적인 내용들
- Akka Actor System에서 성능에 관한 고려 사항들
- dispatcher 설정
- dispatcher thread pool 정적 크기 변경
- thread 해제 방식 변경
- mailbox의 데이터 정보 추출
- 서비스처리 정보 추출
service에 있어 성능에 관한 일반적인 것들과 Akka actor system에서의 특징에 따른 성능에 관한 사항을 정리 해본다.
성능에 관한 일반적인 내용들
-
병목현상(bottleneck)
전체 system 의 성능을 한정시키는 부분 주로 block 인 부분에서 발생됨 -
Throughput(스루풋)
일정한 시간동안 요청을 처리 할 수 있는 작업의 수 -
Service 속도
일정한 시간동안 요청을 처리한 평균 작업수 -
Service(서비스시간)
한 작업을 처리하는데 걸리는 시간 -
Latancy(지연시간)
요청에 대한 응답 처리하는데 지연 혹은 대기 되는 시간 -
Pareto Principle
20%의 문제를 해결하면 80%의 성능 향상을 가져 온다. -
disminishing return(수확체감)
두번째 개선에 따른 효과 크기는 처음 개선의 따른 효과 크기보다 작다. 이는 개선의 증가에 따른 시스템 자원의 효율의 극대로 인한 성능개선의 효과가 기울기가 완만해진다. 따라서 이때는 scale out를 고려 할 수 있다. -
Utilization (가동률)
어떠한 작업의 일을 처리함에 있어 그 것을 처리하는데 소요된 전체에 대한 비율
예) 가동율 50% => 일을 하는데 50% 시간을 소비하고 50%는 유휴 시간
Akka Actor System에서 성능에 관한 고려 사항들
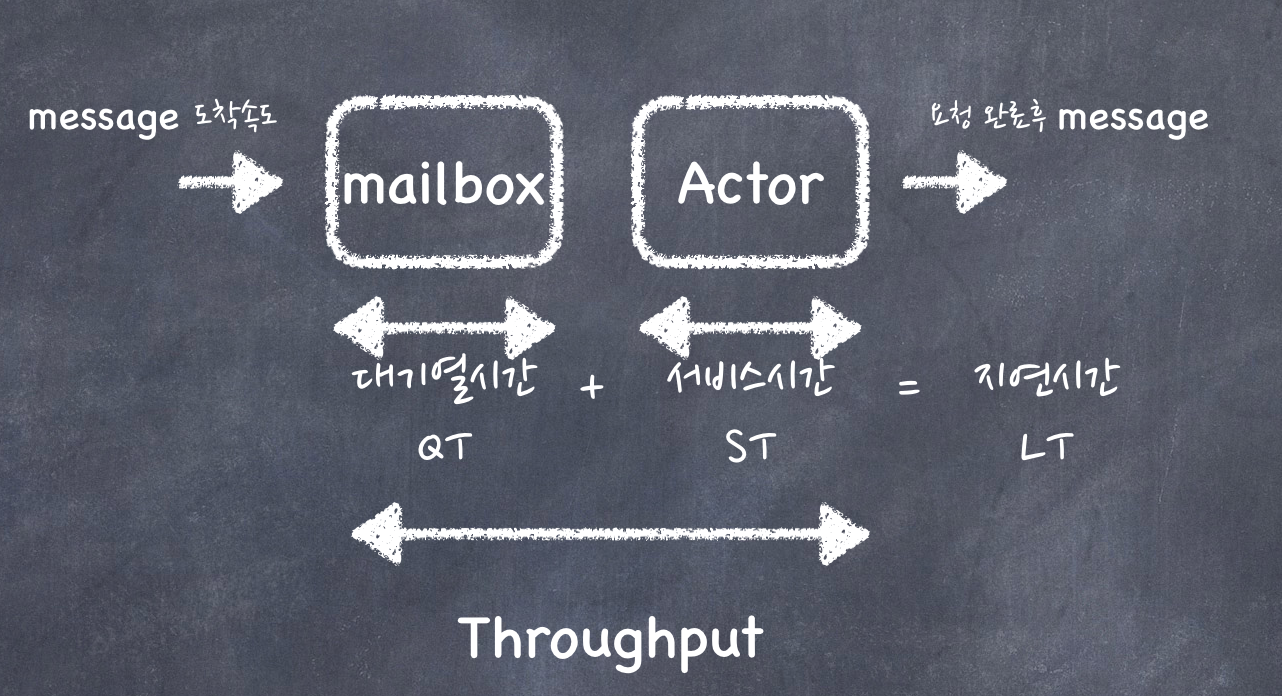
scale out이 아닌 단일 node단위의 성능에 관한 사항은 위에 그림에서 보면 결국 mailbox의 대기열시간, 서비스 시간, 가동율에 따른 thread pool 의 조절이 핵심이다.
- cpu와 thread 상관 관계
thread 갯수 와 정비례하여 성능이 좋아 지는 것은 아니다. cpu core 에 해당하는 최적의 thread갯수가 존재 하며, 최적의 thread 갯수를 초과시 성능은 오히려 하락하다.
이는 cpu 문맥전환에 따른 overhead 및 cpu 경쟁 점유등에 따른 문제에 기인 된다.
akka system에서 병목지점 해결 방법
- router 기법처럼 service actor 증가
- filtering 이 가능하다면 처리대상 도착 메시지를 줄이기
- 실제 service 처리 시간 단축
cpu, memory, disk 등의 자원이 여유가 있을 경우 router 기법을 적용하면 throughput의 향상을 쉽게 가져 올 수 있다. 만약 그러하지 못하다면 scale out 를 고려 할 수 도 있다.
처리대상의 filtering 이 있다면 이를 처리 앞단에 배치하여 설계 함으로써 처리대상 자체의 모수를 줄이게 한다.
이미 서비스 되고 있는 곳에서 block 호출등이 있는지 찾아 보고 개선여지가 있는지 검토
dispatcher 설정
서비스시간(10ms) < 도착시간(15ms) 인데도 불구하고 mailbox에 계속해서 message가 쌓이거나, 가동률이 낮은데도 mailbox에 계속 쌓인다면, 처리할 thread의 부족함을 예상 할 수 있다. 따라서 thread갯수를 늘려 줄 수 있는데 이는 가동률이 낮으면 효과를 보기에 적격이지만 이미 cpu를 다른 곳에서 많이 사용하고 있다면 오히려 느려 질 수가 있다.
dispatcher thread pool 정적 크기 변경
정적 크기
fork-join-executor = {
parallelism-min = 8 # 최소 thread 수
parallelism-factor = 3.0 #가용 processor 대비 thread 수를 계산시 가중치
parallelism-max = 64 # 최대 thread 수
}위의 설정이고 core수가 2개 인경우 min값은
min = 2 x 3.0 = 6개 하지만 min 8 이므로 8이 된다.
factor 생략시 가용 processor와 상관하지 않고 min, max 값 적용 한다.
동적 크기
동적크기 적용시 dispatcher executor를 변경해야 함. default는 fork-join-executor 이를 thread-pool-executor로 변경
dynamic-pool-dispatcher {
type = "Dispatcher"
executor = "thread-pool-executor" # 실행기를 변경
thread-pool-executor {
#fork-join-executor option과 의미가 같다.
core-pool-size-min = 8
core-pool-size-factor = 3.0
core-pool-size-max = 64
# 최대 pool 크기지정
core-pool-size-min = 8
core-pool-size-factor = 3.0
core-pool-size-max = 64
#대기열 유형
task-queue-type = "linked"
#thread pool 크기를 증가시 조건
# 2를 준다면 thread 수 보다 요청수가 2개 많을 경우 증가
# -1 인 경우 증가 하지 않겠다는 의미
task-queue-size = -1
#thread 유휴상태 최대 시간, 이 시간 이후 제거
keep-alive-time = 60s
#핵심 thread도 timeout를 허용하게 한다.
allow-core-timeout = on
}
}thread 해제 방식 변경
throughput 설정
thread들을 처리를 위해 processor는 문맥전환에 따른 overhead가 발생한다.
이와 비슷하게 actor가 message 처리할때 thread가 필요하다.
mailbox의 data가 쌓여 있다면 하나씩 처리하고 thread를 pool에 반납하고, 다시 thread 를 받아 한건 처리하는 것 보다는 batch의 chunk처리처럼 일정 갯수를 처리하고 전환하게 설정 하게 함으로써 성능을 향상 시킬 수 있다. 하지만 이것이 무조건 옳은 방법이 아닐 수 있다. 만약 chunk 단위씩 처리하는 Actor가 비싼 비용을 치러야 하는 연산을 해야 한다면, 다른 어떤 Actor의 가동률은 0가 될 수 도 있다.
sample-pool-dispatcher {
fork-join-executor = {
...
}
#actor가 thread를 pool에 돌려 주기 전에 최대 몇 개의 메시지를 처리할 수 있는지 지정
throughput = 5
}deadline-time 설정
위의 throughtput 설정으로 인한 부작용이 우려 될경우 일정 한계시간을 설정하게 하여 throughput 설정에 도달 하지 않더라도 thread를 pool에 반환 할 수 있게 한다.
sample-pool-dispatcher {
fork-join-executor = {
...
}
throughput = 5
throughput-deadline-time = 300ms
}
default값은 0ms 이다. 즉 마감 시간이 없다.mailbox의 데이터 정보 추출
mailbox 에 message가 들어와서 나가기까지의 시간을 측정함으로써 서비스시간에 따른 대기열의 누적을 예측할 수 있다.
- 정보를 나타낼 case class
- MessageQueue trait 구현
- MailboxType trait 구현 (MailboxType은 MessageQueue factory라 생각 하면 됨)
- Dispatcher에 구현한 MailboxType 선언
아래의 예는 akka in action에 나온 예제 이다.
정보 case class modeling
//발신자와 메시지 정보가 있다.
import akka.dispatch.Envelope
case class MonitorEnvelope(
queueSize: Int, //대기열 갯수
receiver: String,
entryTime: Long, //mailbox 수신 시간
handle: Envelope)
case class MailboxStatistics(
queueSize: Int,
receiver: String,
sender: String,
entryTime: Long,
exitTime: Long)//mailbox에 나온 시간
MessageQueue 구현
Moniotoring할 MessageQueue의 trait는 4개의 abstract method가 있으며 이를 구현 해야한다.
trait MessageQueue {
def enqueue(receiver: ActorRef, handle: Envelope): Unit
def dequeue(): Envelope
def numberOfMessages: Int
def hasMessages: Boolean
def cleanUp(owner: ActorRef, deadLetters: MessageQueue): Unit
}- cleanUp
해당 mailbox가 삭제시 이가 호출됨. 주로 이때 deadLetters에 쌓여있는 message를 보낸다. - enqueue Envelope를 이 queue에 등록시 호출 됨
- dequeue 다음 message를 얻을 때 호출됨
class MonitorQueue(val system: ActorSystem) extends MessageQueue
with UnboundedMessageQueueSemantics with LoggerMessageQueueSemantics {
private final val queue = new ConcurrentLinkedQueue[MonitorEnvelope]
def enqueue(receiver: ActorRef, handle: Envelope): Unit = {
val envel = MonitorEnvelope(
queueSize = queue.size() + 1,
receiver = receiver.toString(),
entryTime = System.currentTimeMillis(),
handle = handle)
queue add envel
}
def dequeue() : Envelope = {
val monitor = queue.poll()
if(monitor != null ) {
monitor.handle.message match {
case stat: MailboxStatistics => //skip message
case _ =>
val stat = MailboxStatistics(
queueSize = monitor.queueSize,
receiver = monitor.receiver,
sender = monitor.handle.sender.toString,
entryTime = monitor.entryTime,
exitTime = System.currentTimeMillis()
)
system.eventStream.publish(stat)
}
monitor.handle
}
else null
}
def numberOfMessages = queue.size()
def hasMessages = !queue.isEmpty()
def cleanUp(owner: ActorRef, deadLetters: MessageQueue): Unit = {
if(hasMessages) {
var envel = dequeue
while(envel ne null) {
deadLetters.enqueue(owner, envel)
envel = dequeue
}
}
}
}MailboxType 구현
class MonitorMailboxType(settings: ActorSystem.Settings, config: Config)
extends MailboxType with ProducesMessageQueue[MonitorQueue] {
final override def create(owner: Option[ActorRef],
system: Option[ActorSystem]): MessageQueue = {
system match {
case Some(sys) => new MonitorQueue(sys)
case _ => throw new IllegalArgumentException("requires a system")
}
}
}위의 코드와 같은 생성자 parameter가 있어야 한다.
전에 만들었던 ActorSystem를 인자로 MessageQueue를 생성한다.
dispatcher에 mailboxType mapping 하기
방법은 설정에 custom-dispatcher를 선언하면서 그 곳에 MailboxType를 선언해 준다.
그 후 code에서 Actor생성시 다음과 같은 방법으로 선언한다.
# application.conf
custom-dispatcher {
mailbox-type = com.sslee.performance.MonitorMailboxType
}
//source level
val act = system.actorOf(Props[MyActor].withDispatcher("custom-dispatcher"))하지만 위의 방법은 모니터링 대상 Actor생성시 위와 같이 소스 코드을 수정 해야 한다.
이 방법은 그리 좋아 보이지 않음..
다른 방법으로는 설정에 아예 default mailboxtype을 해당 mailboxType으로 변경하고 실행시 이 설정 file 명만 다르게 agruement로 주면 된다.
akka {
actor {
default-mailbox {
mailbox-type = com.sslee.performance.MonitorMailboxType
}
}
}서비스처리 정보 추출
이는 template method pattern 처럼 서비스처리시 정보를 생성 -> 변경로직 -> 정보발행 의 template method를 trait Actor를 만들어 제공하고 이 trait를 실제 대상 Actor가 확장한다는 방식이다. 어쩔수 없이 Monoitoring용을 위한 코드가 실제 서비스 코드에 들어 가야 되어서 좀 그렇다… 우째든 code는 다음과 같다.
Template method를 가지는 trait
trait MyMonitorActor extends Actor {
abstract override def receive = {
case msg: Any =>
val start = System.currentTimeMillis()
super.receive(msg)
val end = System.currentTimeMillis()
val stat = ActorStatistics(
self.toString,
sender.toString,
start,
end)
context.system.eventStream.publish(stat)
}
}대상 actor
class ServiceActor01(latencyTime: Duration) extends Actor with ActorLogging {
def receive = {
case msg =>
Thread.sleep(latencyTime.toMillis)
}
}